How Actian Zen Makes Logging Data More Accessible and Useful
Flat files are frequently used by developers because they’re quick and easy to set up. In particular, flat files are often used for application and system logs, where status and error messages are written to a file, one after the other.
Writing log data to a file is easy, but what happens when that data must be shared or when crucial log details must be found? This is where using Actian Zen provides much more flexibility.
Let’s look at some common scenarios – logging application data, retrieving log data, and finding crucial information within a log – to see why it makes sense to store your log files in a Zen data file.
This page covers the topics listed at right.
Logging to Flat Files
Writing log data to a flat file is simple and the files are generally thought of as being portable, which is why applications have traditionally defaulted to using them. Writing entries is simply a matter of opening a file, appending the new entries, and closing the file handle, like so:
void logEvent(string source, string event, int priority, string category)
{
ofstream logFile("application.log", ofstream::out | ofstream::app);
logFile << source << ", " << event << ", "
<< priority << ", " << category << endl;
logFile.close();
}
Someone reading the log file or writing code to handle it will need to know what’s being stored in each of the fields. Fields within a flat text file are all stored as text strings. If the data that a string represents was meant to be of some other data type (such as a number), the values will need to be parsed.
Reading from the file for processing requires more code than writing to it. It involves grabbing one line of the file at a time, then breaking that line into fields, each of which may represent different data types. For some data types, the isolated fields that hold their values may require parsing and conversion before the value can be processed properly.
struct Date {
unsigned char month;
unsigned char day;
unsigned int year;
};
struct LogEntry {
string source;
string event;
int priority;
string category;
};
void logEvent(string source, string event, int priority, string category)
{
ofstream logFile("application.log", ofstream::out | ofstream::app);
logFile << source << ", " << event << ", " << priority << ", "
<< category << endl;
logFile.close();
}
bool readLogEntry(ifstream& inputStream, string& source, string& event,
int& priority, string& category)
{
string line;
vector<string> fieldList;
string token;
if (getline(inputStream, line))
{
istringstream fieldStream(line);
while (getline(fieldStream, token, ',')) {
fieldList.push_back(token);
}
source = fieldList[0];
event = fieldList[1];
priority = stoi(fieldList[2]);
category = fieldList[3];
return true;
}
return false;
}
bool readAllLogs(string sourceLogFile)
{
vector<LogEntry> logEntryList;
ifstream inputStream(sourceLogFile);
if (!inputStream.good())
return false;
while (inputStream.good())
{
LogEntry entry;
if (readLogEntry(inputStream, entry.source, entry.event,
entry.priority, entry.category))
logEntryList.push_back(entry);
}
}
Suppose you were interested in only those log entries in your flat file that had certain attributes. The only way to find them would be to scan the entire file. For small log files, this isn’t much of an issue. But as the log file becomes larger, more data needs to be processed to find entries, which requires more time. For example, finding records containing a maximum or minimum value requires that the records be sorted, and that means they must all be read into memory.
Security is another issue. It’s easy enough to copy a flat file to another system, but the information in the file isn’t necessarily meant for all to read. The only protection a flat file has is whatever is provided by the operating system. Restrictions on who can access the file are handled with an access control list (ACL). Once the file is copied to another computer, the ACL no longer restricts the file in any way.
A third issue is multisource access. Suppose you have multiple applications, or multiple instances of an application, running on a single machine. With flat files, you typically have to manage separate files for each application, which can make searching, sorting, and analysis more complicated. With a Zen data file, it is easy to share a single file among multiple applications, with all the inherent ACID capabilities of Zen protecting the data.
Logging to a Zen Data File
Now let’s consider the same scenario, but instead using a Zen data file.
With Zen data files, we can define the structure for our logged data. The data stored in the table is strongly typed and stored in a form that can be easily analyzed and processed. We can use standard SQL commands to access the data through an ODBC driver, or use Btrieve 2 API functions for quickly writing to or reading from the data file without using SQL. The actual files that make up the database can be saved on the same computer or on a remote computer.
You can also define a structure in code that matches the fields of your file. The Btrieve 2 API can read directly from the file into instances of the structure. Unlike the code for flat files, no additional parsing is needed to load the values to memory.
You do need to set a few compiler options to ensure that the structure for a record has the memory layout that Btrieve 2 expects. Some compilers will insert extra, unused fields into a structure so that memory addresses are aligned on 16- or 32-bit boundaries. If this setting is turned off, the extra fields won’t be inserted into the struct and the memory layout will match.
To demonstrate, let’s create an Zen-based event log that holds the same information as our previous example. We’ll also add an ID field for each. This is what the table looks like in Zen Control Center:
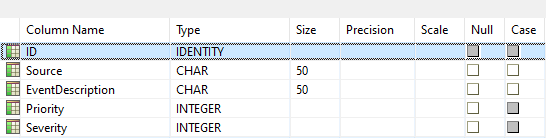
The ID, Priority, and Severity fields are all integers within the structure, while Source and EventDescription are each an array of characters.
Now let’s define a structure for holding these in memory.
struct Event {
int ID;
char source[51];
char eventDescription[51];
int priority;
int severity;
};
Notice in the structure that the Source and EventDescription fields are 51 characters, while in the screenshot above these fields held 50 characters. The reason they take up 51 characters in the struct is to make room for the null terminator of the string. Since the very last character in the string must be a binary 0, if the fields were set to a size of 50, they’d only hold up to 49 characters, with the last character being the null terminator value.
To write one of these events to a file using Btrieve 2, we open the file, write the record, and then close the file:
void writeEvent(Event* event)
{
BtrieveClient btrieveClient;
BtrieveFile btrieveFile;
btrieveClient.FileOpen(&btrieveFile, FILE_NAME, NULL, Btrieve::OPEN_MODE_NORMAL);
btrieveFile.RecordCreate((char*)&event, sizeof(event));
btrieveClient.FileClose(&btrieveFile);
btrieveClient.Reset();
}
In the flat file sample, we defined a custom function that would read a single record from the file. However, the Btrieve 2 API already includes a function for reading a record. In this sample, notice that the function calls we need to parse integer values in the flat file example are gone since they aren’t needed anymore. The following code reads the entire log:
void readAllRecords(BtrieveFile& btrieveFile,vector<Event>& eventList )
{
Btrieve::StatusCode status;
Event event;
int bytesRead = btrieveFile.RecordRetrieveLast(Btrieve::INDEX_NONE,
(char*)&event, sizeof(Event));
while (status == Btrieve::STATUS_CODE_NO_ERROR )
{
eventList.push_back(event);
btrieveFile.RecordRetrievePrevious((char*)&event, sizeof(event));
status = btrieveFile.GetLastStatusCode();
}
}
void openAndReadLogFile()
{
BtrieveClient btrieveClient;
Btrieve::StatusCode status;
BtrieveFile btrieveFile;
Event event;
status = btrieveClient.FileOpen(&btrieveFile, FILE_NAME, NULL,
Btrieve::OPEN_MODE_NORMAL);
if (status != Btrieve::STATUS_CODE_NO_ERROR)
return;
vector<Event> eventList;
readAllRecords(btrieveFile, eventList);
btrieveClient.FileClose(&btrieveFile);
}
Not only is reading from the log easier now, finding records within it also is much simpler. The Btrieve 2 API includes functionality for indexing the file. When the file is indexed, search and filtering operations can be performed more efficiently and with less code. Indices can be built by code as needed.
Let’s consider a scenario where an index might help. Suppose the top 20 events with the highest severity must be retrieved. One way to do this is to create an index based on the severity field. When two events are of the same severity, we want the one with the highest priority to be returned first. We’ll create an index based on these two fields.
The index must be assigned an index number. When you want to use the index, you select using the number it was assigned. INDEX_1 is already being used for the ID field of our event, leaving the values INDEX_2 up to INDEX_119 available for use. The following code creates an index on the severity and priority fields. Since we want the highest values to be returned first, the fields used in the index are set to use descending order.
void createSeverityIndex(BtrieveFile& btrieveFile, Btrieve::Index indexNumber)
{
BtrieveIndexAttributes severityIndexAttributes;
BtrieveKeySegment severityKeySegment, priorityKeySegment;
Btrieve::StatusCode status;
severityKeySegment.SetField(108,4,Btrieve::DATA_TYPE_INTEGER);
severityKeySegment.SetDescendingSortOrder(true);
severityIndexAttributes.AddKeySegment(&severityKeySegment);
priorityKeySegment.SetField(104, 4, Btrieve::DATA_TYPE_INTEGER);
priorityKeySegment.SetDescendingSortOrder(true);
severityIndexAttributes.AddKeySegment(&priorityKeySegment);
btrieveFile.IndexCreate(&severityIndexAttributes);
}
With just a few small modifications, the code we used to read all the records from the data file will now retrieve the 20 most severe events. In the modified version, the index number to be used for sorting is now passed in an argument. When a call is made to read the first record, this index number is used.
In the previous version of this function, the index was set to INDEX_NONE so the records were retrieved in no specific order. Now the records are being retrieved in a definite order. Note that we didn’t need to write any sorting code.
void readMostSevereRecords(BtrieveFile& btrieveFile, vector<Event> eventList, Btrieve::Index index)
{
Btrieve::StatusCode status;
Event event;
int bytesRead = btrieveFile.RecordRetrieveFirst(index, (char*)&event, sizeof(Event));
while (status == Btrieve::STATUS_CODE_NO_ERROR && eventList.size()<20)
{
eventList.push_back(event);
btrieveFile.RecordRetrieveNext((char*)&event, sizeof(event));
status = btrieveFile.GetLastStatusCode();
}
}
If we need to handle multiple sort orders, we could create several indices in a file. To retrieve records using an index in reverse order, we’d use the RecordRetrieveLast and RecordRetrievePrevious functions instead of RecordRetrieveFirst and RecordRetrieveNext.
If we decide we no longer need the index, deleting it is a single function call to BtrieveFile::IndexDrop. Indexes can be created in or dropped from existing data files at any time. Once created, they are automatically maintained for all subsequent CRUD operations.
As with flat files, access to the Zen data file can be restricted using file permissions from the operating system. With a Zen data files, you can also use file encryption (see SetOwner()) to provide the file with another layer of protection from unauthorized access.
Wrapping Up
Using Zen DB for a logging solution has several benefits:
- Information logged to the data file is strongly typed instead of written as text that might have different interpretations.
- There’s no need to parse data when reading it from the data file.
- A program can quickly find entries of interest or ordered information using the Btrieve 2 API, ODBC, or any access method supported by Zen.
- Security, encryption, ACID, and all standard data management features are available for your logged data.
To learn more about the Btrieve 2 classes, see the Btrieve C++ and C API page. To download the Btrieve 2 SDK, visit the Actian Electronic Software Distribution site.